
はじめに
この記事は、DeepSeekの内容でありLLM V3とR1についての性能の詳細と何が違うのかの比較を綴った記事になっています。
大まかなDeepSeekについては、前回の記事を参考にしてもらえばなと思います。
また、そんな記事よりソースを見たいという方のために先にソース元のURLを記載します。
当てはまる方は、以下のURL,記事をアクセスしてください

DeepSeek V3
DeepSeekは、最新のAI技術を駆使して開発されたLLM(大規模言語モデル)であり、その性能は業界内外で大きな注目を集めています。特に、最新モデルであるDeepSeek-V3は、前世代からの飛躍的な進化を遂げています。
DeepSeek-V3の主な特徴
- 圧倒的なパラメータ数:DeepSeek-V3は、6710億のパラメータを持つMixture-of-Experts(MoE)アーキテクチャを採用しています。この構造により、37Bのパラメータが各トークンに対して活性化され、高度な情報処理を可能にしています。
- 高速な推論速度:前世代のモデルと比較して、DeepSeek-V3は推論速度において大幅な改善を実現しています。具体的には、毎秒60トークンの生成が可能であり、これは前世代モデルと比較して約3倍の速度向上となります。
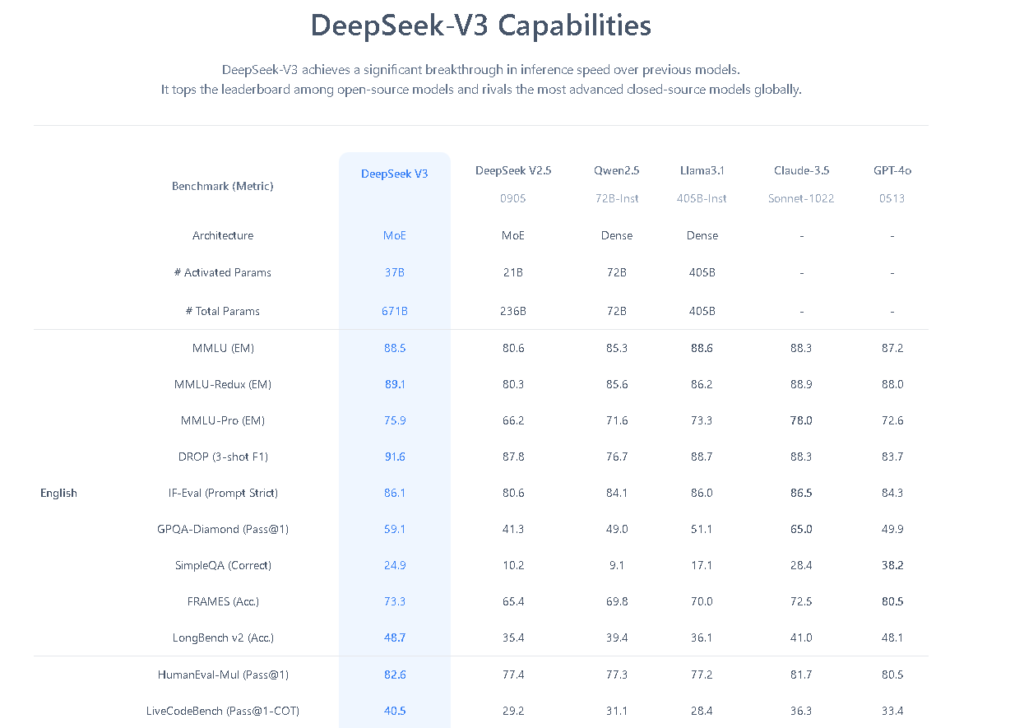
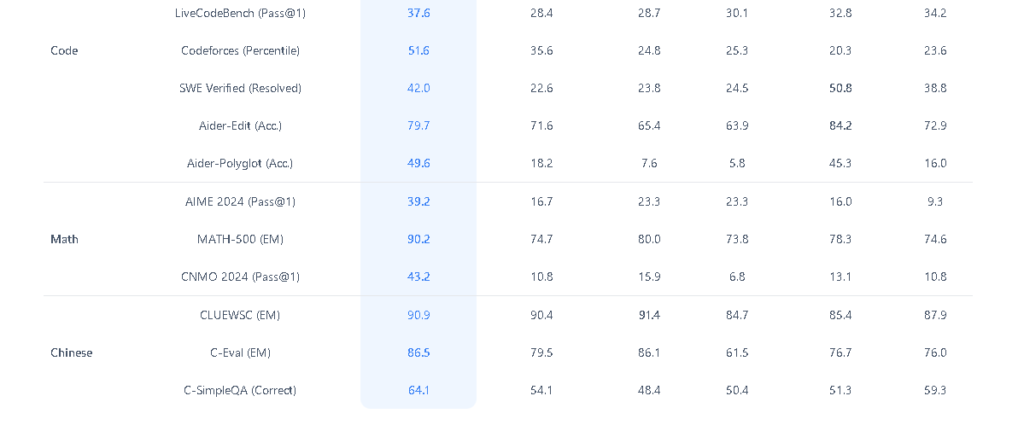
- 多様なベンチマークでの高性能:DeepSeek-V3は、以下のベンチマークテストで優れた成績を収めています:
- MMLU(英語):88.5%MMLU-Pro:75.9%DROP(3-shot F1):91.6%Code HumanEval-Mul(Pass@1):82.6%Math AIME 2024(Pass@1):39.2%C-Eval(EM):86.5%
- 効率的なアーキテクチャ設計:DeepSeek-V3は、Multi-head Latent Attention(MLA)とDeepSeekMoEといった革新的なアーキテクチャを採用しています。これにより、推論時の効率性が向上し、計算資源の節約と高い性能の両立を実現しています。
DeepSeek-V3の活用方法
DeepSeek-V3は、ウェブ版、アプリ、APIを通じて利用可能です。特に、APIを活用することで、ビジネスアプリケーションへの統合が容易になり、さまざまな業務プロセスの効率化や自動化を支援します。
まとめ
DeepSeek-V3は、最新のAI技術を駆使したLLMであり、その性能と効率性は業界内外で高く評価されています。特に、膨大なパラメータ数と高速な推論速度、多様なベンチマークでの高い性能は、今後のAI活用において大きな可能性を秘めています。
DeepSeek R1
DeepSeek-R1は、中国のAI企業DeepSeekが開発した最新のAIモデルであり、その性能と革新性で注目を集めています。特に、DeepSeek-R1は、OpenAIのモデルに匹敵する能力を持ちながら、商用利用が可能な点で大きな話題となっています。
DeepSeek-R1の主な特徴
- 大規模なパラメータ数:DeepSeek-R1は、6710億のパラメータを持つ大規模モデルであり、複雑な推論タスクにおいて高い性能を発揮します。
- オープンソースと商用利用:MITライセンスのもとで提供されており、商用利用や再配布が自由に行えます。これにより、企業や開発者はモデルを自由に活用し、独自のアプリケーションやサービスに組み込むことが可能です。
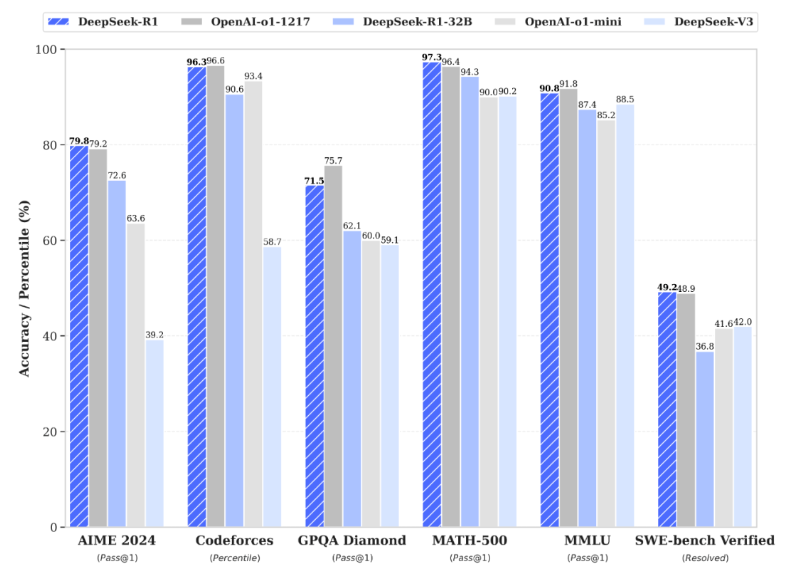
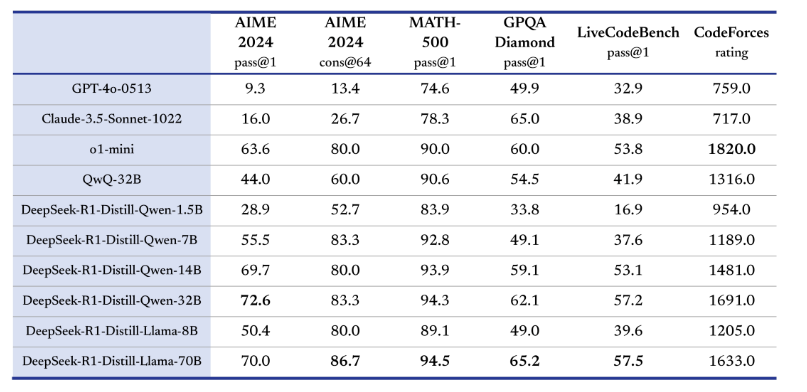
- 高いベンチマークスコア:DeepSeek-R1は、AIME、MATH-500、SWE-bench Verifiedなどのベンチマークテストで、OpenAIのモデルを上回る結果を記録しています。具体的には、数学的問題の解決において97%の精度を達成し、プログラミングテストでは人間の96%を上回る性能を示しています。
- 効率的なリソース使用:DeepSeek-R1は、OpenAIのモデルと比較して、約10分の1の計算資源で同等の性能を実現しています。開発コストも約600万ドルと、他の大規模モデルに比べて大幅に低く抑えられています。
- 蒸留モデルの提供:DeepSeek-R1から派生した、1.5億から70億パラメータの蒸留モデルも公開されており、最小サイズのものは家庭用PCでも動作可能です。これにより、一般ユーザーでも高度なAI技術を手軽に利用できます。
DeepSeek-R1の活用方法
DeepSeek-R1は、公式サイト上で無料で利用可能であり、API経由での提供も行っています。特に、APIを活用することで、ビジネスアプリケーションへの統合が容易になり、さまざまな業務プロセスの効率化や自動化を支援します。
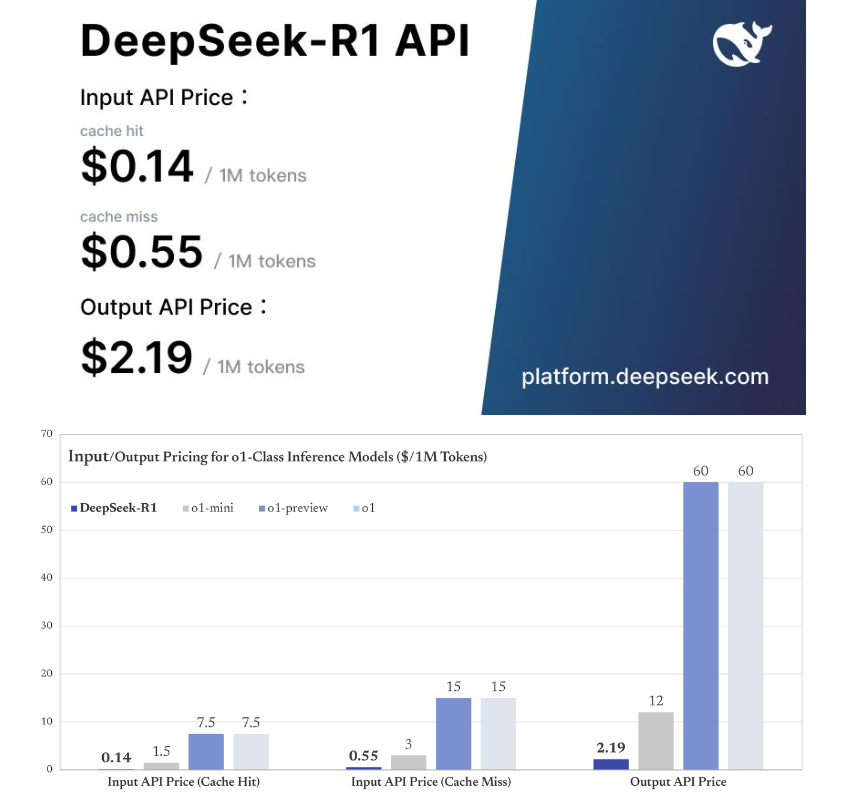
まとめ
DeepSeek-R1は、最新のAI技術を駆使したモデルであり、その性能と効率性、そしてオープンソースとしての柔軟性は、今後のAI活用において大きな可能性を秘めています。特に、商用利用が可能な点や、効率的なリソース使用は、企業や開発者にとって大きな利点となるでしょう。
DeepSeek V3 と R1 比較 違い
DeepSeek-V3とDeepSeek-R1は、いずれも中国のAI企業DeepSeekが開発した最新のAIモデルです。両者は高い性能を誇りますが、その設計思想や用途には明確な違いがあります。
以下に、最新の情報を基に、性能や使い方の違いを分かりやすく解説します。
1. モデルの概要と開発背景
- DeepSeek-R1:DeepSeekが初めて公開した大規模言語モデルであり、OpenAIのモデルに匹敵する性能を持ちながら、商用利用が可能な点で注目を集めました。開発コストは約600万ドルと、他の大規模モデルに比べて大幅に低く抑えられています。
- DeepSeek-V3:DeepSeek-R1の成功を受けて開発された次世代モデルであり、6710億のパラメータを持つMixture-of-Experts(MoE)アーキテクチャを採用しています。前世代からの飛躍的な進化を遂げ、さらなる性能向上と効率化を実現しています。
2. パラメータ数とアーキテクチャ
- DeepSeek-R1:具体的なパラメータ数は公開されていませんが、効率的なリソース使用と高い性能を両立しています。特に、OpenAIのモデルと比較して、約10分の1の計算資源で同等の性能を実現しています。
- DeepSeek-V3:6710億のパラメータを持ち、MoEアーキテクチャを採用することで、各トークンに対して37Bのパラメータが活性化されます。これにより、高度な情報処理と効率的な計算を可能にしています。
3. 性能とベンチマーク結果
- DeepSeek-R1:AIMEやMATH-500などのベンチマークテストで、OpenAIのモデルを上回る結果を記録しています。具体的には、数学的問題の解決において97%の精度を達成し、プログラミングテストでは人間の96%を上回る性能を示しています。
- DeepSeek-V3:多様なベンチマークテストで優れた成績を収めており、特にHumanEval-MulやCNMO 2024などのプログラミングや数学の分野で他のAIモデルに対して際立った結果を示しています。
4. 利用方法と商用利用の可否
- DeepSeek-R1:MITライセンスのもとで提供されており、商用利用や再配布が自由に行えます。これにより、企業や開発者はモデルを自由に活用し、独自のアプリケーションやサービスに組み込むことが可能です。
- DeepSeek-V3:オープンソースとして公開されており、ソースコードやモデルがGitHubからダウンロード可能です。API経由での提供も行っており、ビジネスアプリケーションへの統合が容易になっています。
5. コストとリソース効率
- DeepSeek-R1:開発コストは約600万ドルで、OpenAIのモデルと比較して大幅に低コストで開発されています。また、約10,000のNVIDIA製GPUを使用して効率的にトレーニングされています。
- DeepSeek-V3:トレーニングにはNVIDIA H800を約278万8000GPU時間使用し、約557万ドルの費用を要しました。大規模なパラメータ数を持ちながら、効率的なアーキテクチャ設計により、高い性能とリソース効率を実現しています。
6. モデルの発表時期について
DeepSeek-R1:2025年1月に発表されました。
DeepSeek-V3:2024年12月に発表されました。
まとめ
DeepSeek-R1は、商用利用を視野に入れた高い性能と効率性を持つモデルとして登場しました。一方、DeepSeek-V3は、さらに大規模なパラメータ数と高度なアーキテクチャを採用し、より高度なタスクへの対応や効率的な計算を実現しています。利用目的や必要な性能に応じて、これらのモデルを選択・活用することが重要です。

